CGX
Distributed training framework with communication compression support
CGX represents a collection of approaches for efficient integration of gradient compression in distributed DNN training frameworks.
The first approach is the clone (not public) of Horovod framework. We integrate the gradient compression logic into communication layer and add filtering of the communicated layers.
The second approach is QNCCL. Here, we integrate gradient compression logic into NCCL kernels.
The third approach is pytorch-cgx. pytorch-cgx is a plug-in extension for torch.distributed that substantially improves scalability on servers with low-bandwidth inter GPU communication. Keep your training scripts the same, only need to replace torch.distributed backend and launching script. The only changes to the training script using pytorch distributed required are importing the built extension and specifying cgx as torch.distributed.init_process_group backend parameter and setting some environment variables.
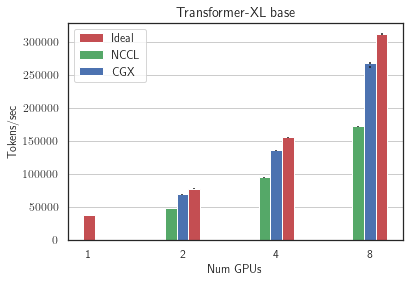
Applying CGX to distributed training on a single machine with 8xRTX3090 allows us to achieve 60% speedup compared to the Nvidia NCCL: